
游标翻页

游标翻页
乐深翻页问题
普通翻页前端一般会有个分页条。能够指定一页的条数,以及任意选择查看第几页。
对应的参数就是pageNo和pageSize
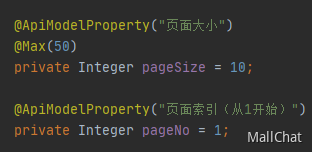
假设前端想要查看第11页的内容,传的值pageNo=11,pageSize=10
对于数据库的查询语句就是。
1 | select * from table limit 100,10 |
其中100代表需要跳过的条数,10代表跳过指定条数后,往后需要再取的条数。
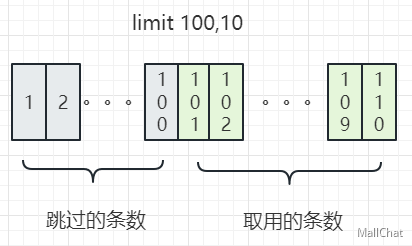
对应图片就是这样的一个效果,需要在数据库的位置先读出100条,然后丢弃。丢弃完100条后,再继续取10条选用。
如果我们翻页到了很深的地方,比如读到了第1000页,对应的sql语句就是
1 | select * from table limit 10000,10 |
需要先查询10000条进行丢弃,再取那么个10条选用。这个效率也太低了,
我们经常需要定时任务全量去跑一张表的数据,普通翻页去跑的话,到后面数据量大的时候,就会越跑越慢,这就是深翻页带来的问题。
有没有解决办法呢?有!
好好思考下,目前的问题在于每次翻页都需要花时间扫描一些不需要的记录,然后丢弃。那么是不是可以优化这个步骤呢?
以后不论第几页,我们都不需要跳过一些值。直接取limit 0,10。这样语句变成了
1 | select * from table limit 0,10 |
取到的是1-10这些记录,取不到我们想要的101-110.
没关系,再加一个条件
1 | select * from table where id>100 order by id limit 0,10 |
只要id这个字段有索引,就能直接定位到101这个字段,然后去10条记录。以后无论翻页到多大,通过索引直接定位到读取的位置,效率基本是一样的。这个id>100就是我们的游标,这就是游标翻页。
游标翻页简单介绍
游标翻页可以完美的解决深翻页问题,依赖的就是我们的游标,即cursor。针对mysql的游标翻页,我们需要通过cursor快速定位到指定记录,意味着游标必须添加索引。
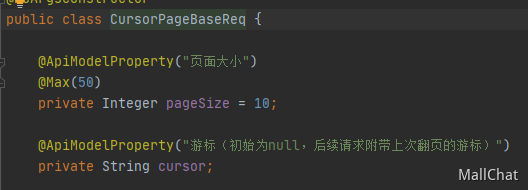
前端之前传的pageNo字段改成了cursor字段。cursor是上一次查询结果的位置,作为下一次查询的游标,由后端返回,具体交互可看抹茶的前端后是如何协作的
我们来模拟一次前后端的翻页交互
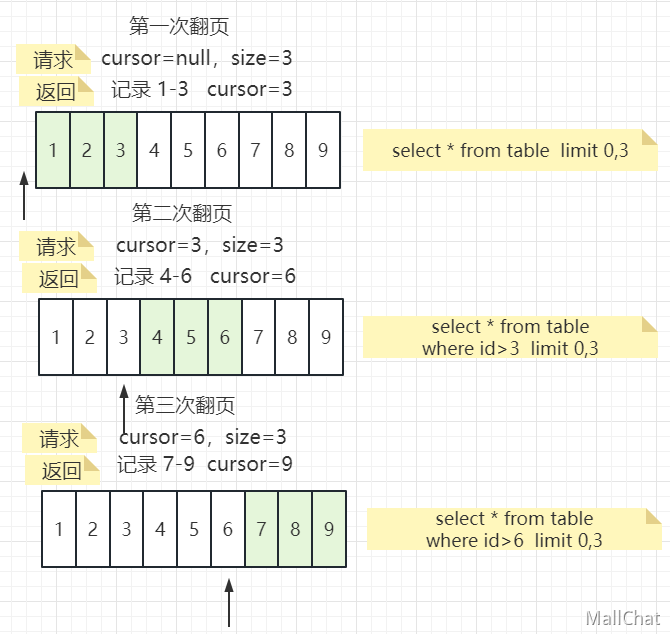
随着翻页的持续,游标不断往翻页的方向推进。
所以游标翻页不适合跳页,只能不断的往下翻。更适合C端的列表场景
总结
游标翻页的优点:
1.解决深翻页问题
2.解决频繁变动的列表翻页问题。
缺点:
1.无法跳页,只能不断往下翻
游标翻页更适合c端场景,用户只能不断下滑翻页。
普通翻页更适合B端场景。用户能看见总页数,能随意跳页
游标翻页技术细节
我们的项目大量使用到了游标翻页,比如会话列表,消息列表,成员列表。其中数据库涉及了redis和mysql。并且封装了分页工具类,接下来就一起看看具体的实现细节。
mysql游标翻页
原生的游标翻页
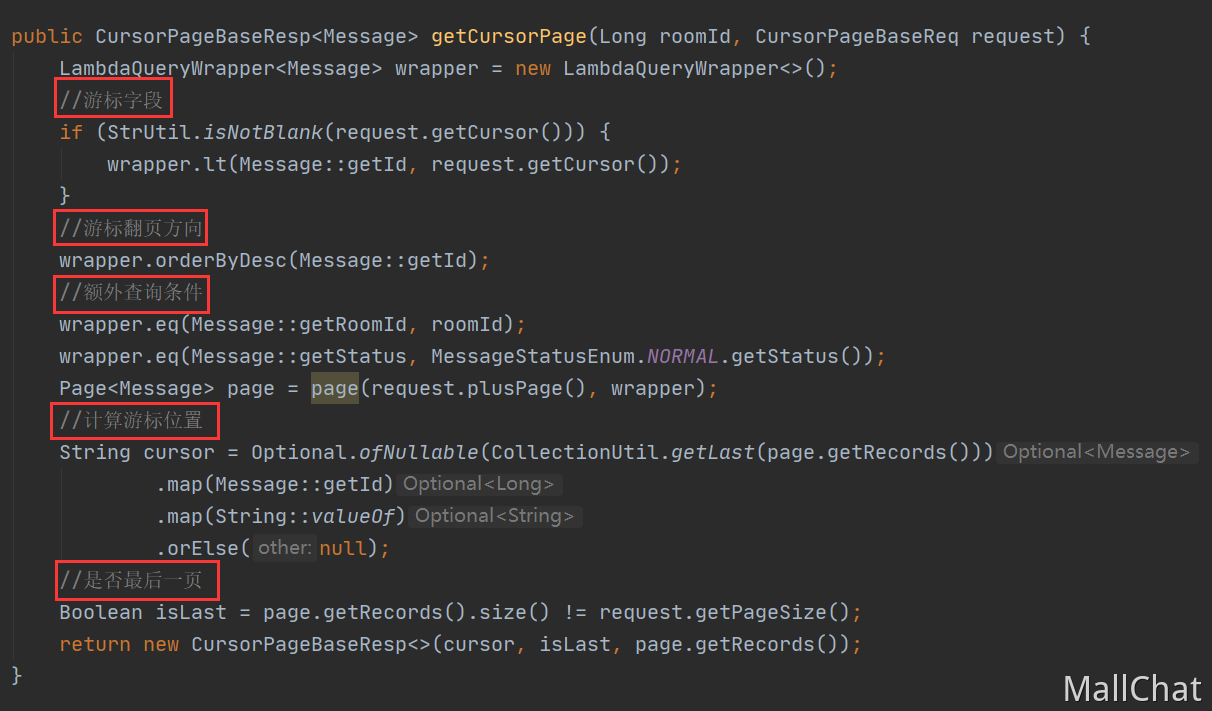
1 | LambdaQueryChainWrapper<UserFriend> wrapper = lambdaQuery(); |
这个是一个完整的游标翻页的写法,也是我们消息列表的游标翻页的写法。
一个游标翻页查询最重要的,就是设定游标,确定方向。
以及查出结果后,要包装给前端的参数 当前游标位置,是否最后一页。
这样的查询基本是一个固定的套路,当你有其他的业务,比如会话列表也需要用到游标翻页,也是按照这个固定套路来进行查询的。
不知道你们觉得这块代码够不够简单,反正我觉得太臃肿了,再写一遍就吐了。
我们可以尝试把固定的游标模板抽出来,把可变的作为入参让业务传进来,形成一个工具类。
通过上面的分析,额外查询条件和游标字段这个是可变的,其他都可以抽出来。
返回:
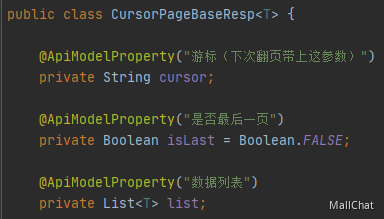
返回的也是可以直接给前端展示的实体类。








